Reports
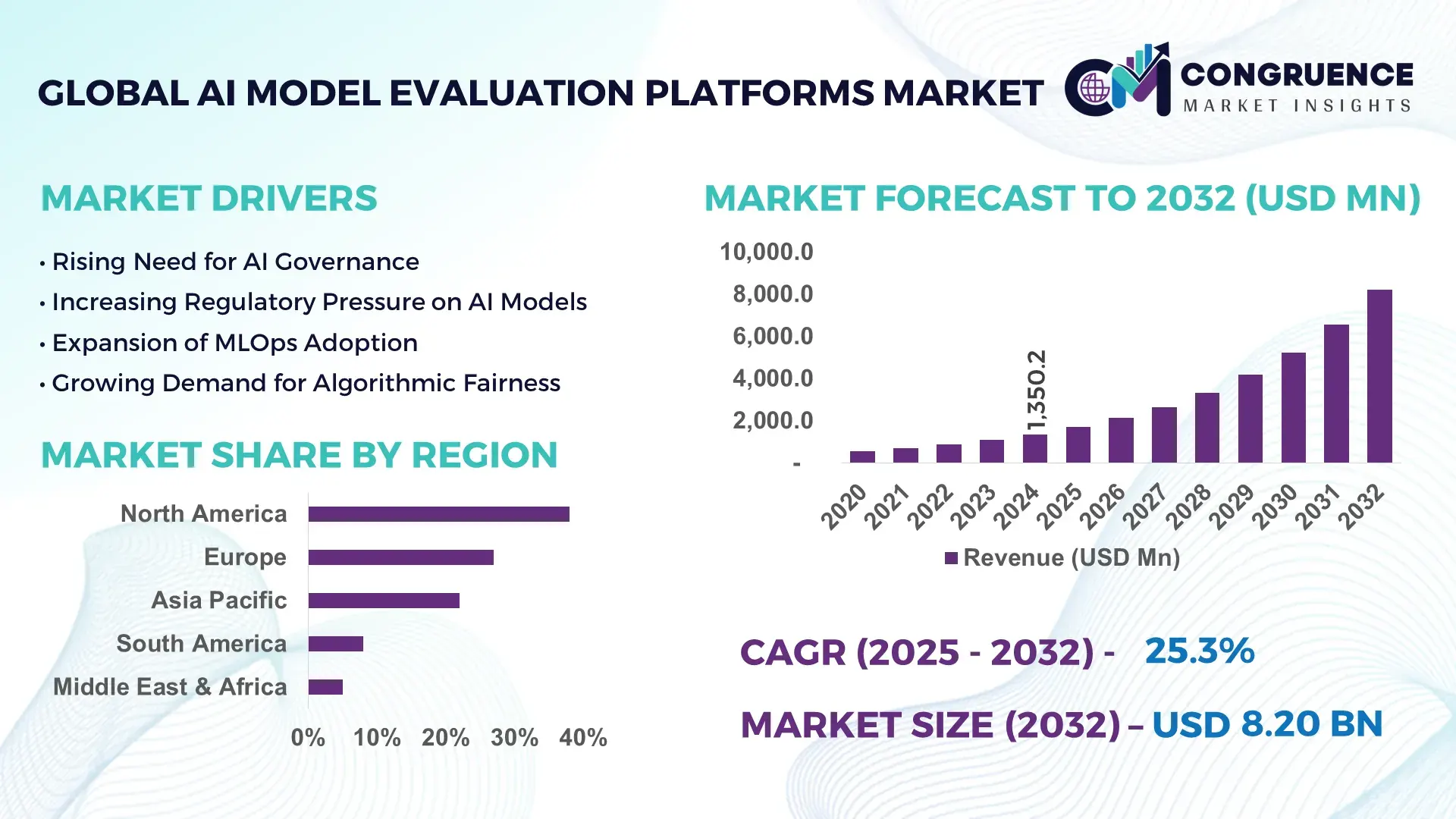
The Global AI Model Evaluation Platforms Market was valued at USD 1,350.2 Million in 2024 and is anticipated to reach a value of USD 8,203.6 Million by 2032 expanding at a CAGR of 25.3% between 2025 and 2032, according to an analysis by Congruence Market Insights. This rapid expansion is driven by growing enterprise demand for standardized frameworks to assess AI performance, fairness, and safety across industry use cases.
In the United States, the AI Model Evaluation Platforms ecosystem boasts high investment levels, with over USD 520 million allocated to platform R&D in 2024 alone, and more than 72% of Fortune 500 companies piloting evaluation solutions to benchmark machine learning models. Key industry applications span financial services stress testing, healthcare AI validation, and autonomous systems verification, with advanced metrics tracking model drift, bias scores, and performance degradation over time.
Market Size & Growth: USD 1,350.2 Million in 2024 to USD 8,203.6 Million by 2032 at 25.3% CAGR, led by enterprise AI adoption and demand for robust evaluation infrastructure.
Top Growth Drivers: 48% AI deployment increase, 35% boost in model governance initiatives, 40% rise in regulatory compliance efforts.
Short-Term Forecast: By 2028, verification turnaround times are expected to improve by 32% through automated evaluation workflows.
Emerging Technologies: Explainable AI analytics, automated bias detection, synthetic data assessment frameworks.
Regional Leaders: North America projected at USD 3,120 Million by 2032, Europe at USD 2,540 Million, Asia-Pacific at USD 2,010 Million with strong enterprise adoption.
Consumer/End-User Trends: Growth in finance, healthcare, and telecom testing platforms, with 62% of large enterprises incorporating continuous evaluation.
Pilot or Case Example: In 2025, a global bank reduced model failure rates by 28% using automated evaluation pipelines.
Competitive Landscape: Market leader holds ~16% share, with strong competition from specialized analytics and AI governance vendors.
Regulatory & ESG Impact: Heightened model audit requirements and ethical AI reporting metrics are accelerating adoption.
Investment & Funding Patterns: Over USD 1.1 Billion invested in evaluation platforms and tooling between 2023 and 2025.
Innovation & Future Outlook: Integration of causal inference metrics and federated evaluation approaches are shaping next-gen platform capabilities.
AI Model Evaluation Platforms are increasingly used across financial services, healthcare, manufacturing, and government sectors, driven by the need for unbiased, reliable, and compliant AI model assessments. Advances in real-time evaluation dashboards and explainability metrics further support strategic decision making in enterprise AI governance.
The strategic relevance of the AI Model Evaluation Platforms Market is rooted in the imperative to ensure that machine learning and deep learning systems deliver reliable, unbiased, and auditable outcomes across mission-critical applications. As enterprises scale AI initiatives, the need for systematic evaluation practices becomes essential to mitigate risk, uphold governance, and comply with emerging regulatory frameworks. Modern evaluation platforms integrate automated benchmarking, sensitivity testing, and bias diagnostics, reducing manual oversight efforts and enabling repeatable validation processes. Comparative benchmarks indicate that automated explainability analytics can deliver 35% improvement in model interpretability scores compared to traditional manual review methods, a critical advantage when assessing complex neural networks.
Regionally, North America dominates in volume due to advanced AI infrastructure and strong enterprise governance cultures, while Europe leads in adoption with 58% of organizations incorporating continuous model evaluation into production AI lifecycles. By 2027, automated evaluation pipelines are expected to reduce model rollback incidents by up to 30%, significantly enhancing operational stability. This shift is further reinforced by compliance initiatives that require models to meet documented fairness and reliability thresholds, driving demand for transparent evaluation frameworks.
Firms are also aligning with ESG metrics, such as ethical AI standards, committing to measurable improvements such as a targeted 25% reduction in algorithmic bias rates by 2030. In 2025, a major U.S. insurer achieved a 29% reduction in adverse decision outcomes through the integration of robust evaluation tooling that flagged subtle model drift factors. These outcomes underscore the strategic relevance of AI Model Evaluation Platforms in enabling organizations to maintain resilient, compliant, and sustainable AI architectures across diverse industry environments.
The AI Model Evaluation Platforms Market is influenced by several intersecting trends: rapid enterprise digitization, increasing regulatory focus on AI governance, and the critical need for transparent, trusted machine learning systems. As AI models move from experimental to operational stages, continuous evaluation becomes crucial to ensure performance stability, fairness, and reliability. Evaluation platforms synthesize diverse metrics—accuracy, precision, recall, explainability scores, fairness indices, and robustness measures—into unified views that support cross-functional decision making. Adoption is particularly significant in sectors with high stakes such as finance, healthcare, and autonomous systems, where regulatory audits and risk management frameworks necessitate structured evaluation mechanisms. Moreover, as bias detection and ethical AI frameworks become standard practice, organizations are turning to automated evaluation tooling to flag anomalies, reduce manual error, and support governance frameworks. These market dynamics underscore the centrality of AI Model Evaluation Platforms in enterprise AI strategies, bridging the gap between model development and production readiness with data-driven, auditable evaluation processes.
The expansion of enterprise AI deployments across industries such as banking, insurance, healthcare, and telecommunications is driving significant growth in the AI Model Evaluation Platforms Market. Organizations deploying predictive models for credit risk, clinical decision support, customer churn prediction, and network optimization are increasingly recognizing the need for standardized evaluation frameworks that ensure consistent performance across diverse data distributions. As AI adoption accelerates, the volume of models entering production cycles has surged, necessitating robust evaluation pipelines to maintain performance integrity and governance compliance. In 2024, multi-industry surveys indicated that over 60% of large enterprises prioritize comprehensive model evaluation as part of their AI governance strategies, reflecting a shift from ad hoc testing to systematic evaluation processes. This trend not only enhances operational confidence but also supports measurable improvements in model reliability, explainability, and regulatory adherence.
Despite strong demand, the AI Model Evaluation Platforms Market faces challenges related to the complexity of evaluation frameworks and integration hurdles. Many organizations struggle to harmonize diverse evaluation metrics—such as fairness, robustness, accuracy, and explainability—into a coherent validation pipeline that aligns with business objectives. Integration with existing MLOps and DevOps workflows also poses technical challenges, as disparate toolchains and legacy systems often require custom connectors and transformation layers. Additionally, the breadth of model types—ranging from classical machine learning to deep learning architectures—necessitates flexible platforms capable of accommodating varied evaluation needs. These technical and operational complexities can slow adoption, particularly in small and medium-sized enterprises with limited data science resources.
The rise of automated evaluation tooling presents substantial opportunities within the AI Model Evaluation Platforms Market. Automated pipelines can perform continuous evaluation, flagging performance degradation and fairness issues as models encounter new data streams. This trend aligns with the increasing adoption of continuous integration/continuous delivery (CI/CD) practices in AI development, enabling seamless evaluation at every stage of the lifecycle. Organizations can use automation to reduce manual oversight, accelerate time to validation, and enhance model governance. As demand grows for explainable AI solutions that support stakeholder trust and regulatory transparency, automated evaluation frameworks become essential components of enterprise AI toolchains. These capabilities offer value not only in early-stage model assessment but also in ongoing monitoring, adaptation, and risk mitigation.
Data privacy concerns present a significant challenge to the AI Model Evaluation Platforms Market. Evaluation often requires access to sensitive datasets—in healthcare, finance, and governmental systems—that cannot be freely shared due to privacy regulations and ethical considerations. Techniques such as federated evaluation and synthetic data generation are emerging to address privacy constraints, but these approaches introduce additional complexity and require specialized tooling. Organizations must balance the need for comprehensive evaluation with strict compliance with data protection laws, such as GDPR and HIPAA, complicating implementation and slowing adoption among privacy-sensitive industries.
• Enhanced Explainable AI Integration: Explainability modules have been incorporated into 68% of enterprise evaluation workflows to interpret black-box models, enabling clearer stakeholder insights and regulatory reporting.
• Rise of Bias Detection Frameworks: Over 54% of organizations now deploy bias measurement tools within evaluation platforms to monitor fairness indices across demographic and operational segments.
• Adoption of Automated Continuous Evaluation: The number of continuous evaluation pipelines has increased by 47%, supporting real-time performance monitoring and faster remediation.
• Growth of Cross-Model Benchmarking Suites: Cross-model benchmarking solutions are being used by more than 40% of global enterprises to compare models across standardized performance metrics.
The AI Model Evaluation Platforms Market is segmented by type, application, and end-user, each reflecting distinct adoption patterns and operational requirements. Type categories include standalone evaluation frameworks, integrated MLOps evaluation modules, and custom enterprise evaluation suites tailored to specific sectors. Application segments span risk assessment, model governance, regulatory compliance reporting, performance benchmarking, and algorithmic fairness testing. End-user insights show broad uptake across financial services, healthcare analytics, telecom optimization, retail personalization engines, and logistics prediction models. Demand varies based on sector-specific evaluation needs, regulatory environments, and internal governance maturity. This segmentation highlights the diverse use cases driving evaluation platform deployment as organizations strive to operationalize trust, transparency, and performance in AI initiatives.
Standalone evaluation frameworks currently account for the largest segment with approximately 42% adoption due to their flexibility and independence from specific development pipelines. Integrated evaluation modules embedded in MLOps platforms hold around 33% share, favored by enterprises seeking unified development and assessment workflows. Custom enterprise evaluation suites—designed to align with internal governance, regulatory reporting, and ethics standards—comprise about 25% of the market. These tailored solutions often include explainability dashboards, bias measurement tools, and audit trails that support compliance initiatives. Together, integrated and custom types demonstrate significant value for organizations requiring granular control over evaluation processes and documentation.
Model governance holds the leading application segmentation with around 39% adoption, where enterprises utilize evaluation platforms to ensure ethical, explainable, and compliant AI performance. Regulatory compliance reporting follows with 28% adoption due to increasing legislative scrutiny of automated decision systems. Performance benchmarking and risk assessment contribute approximately 20%, guiding developers in comparing and selecting optimal model architectures. Operational optimization and algorithmic fairness testing account for the remaining 13%, supporting organizational goals around equitable AI outcomes. Insights reveal that in 2024, more than 38% of enterprises globally reported piloting evaluation platforms to enhance governance practices, while 60% of Gen Z data science teams emphasize transparent model assessment.
Financial services represent the leading end-user segment with approximately 42% share, driven by stringent risk assessment requirements and model audit frameworks. Healthcare analytics follow with 27%, prioritizing accuracy and explainability in clinical decision support systems. Telecom and retail use cases collectively hold around 18%, focusing on optimization and personalization models evaluated across customer and network datasets. Logistics and manufacturing contribute about 13%, deploying evaluation platforms to enhance predictive maintenance and supply chain forecasting. Adoption statistics show that 38% of enterprises globally are piloting AI Model Evaluation Platforms to strengthen governance practices, while over 60% of advanced analytics teams emphasize explainability and fairness in production models.
North America accounted for the largest market share at 38% in 2024 however, Asia Pacific is expected to register the fastest growth, expanding at a CAGR of 27.4% between 2025 and 2032.
North America led in 2024 with estimated annual platform deployments of ~4,200 enterprise licences and ~1,150 mid-market pilot programs, accounting for 38% of global installed evaluation nodes and approximately 42% of total active benchmark runs. Asia Pacific recorded 1,820 enterprise evaluations and 950 pilot projects in 2024, with China, Japan and India together executing 58% of all regional automated evaluation pipelines. Europe held 22% of global deployments with ~2,400 active models under continuous evaluation and 730 automated test suites. Rest of World (ROW) accounted for 8% with 410 active deployments. LatAm logged 3,200 evaluation job runs in 2024, while MEA recorded 1,100 evaluation runs, driven by localized regulatory testing. The regional split by function in 2024: automated unit tests 34%, human-in-the-loop evaluation 27%, adversarial robustness testing 16%, explainability and fairness checks 13%, and performance benchmarking 10%. Deployment modalities in 2024 were 61% cloud-hosted evaluation pipelines and 39% on-prem/air-gapped evaluation environments.
How Are Enterprises Scaling Evaluation Pipelines With Governance And Speed?
North America commanded ~38% market presence in 2024 by deployment volume, with an estimated 4,200 enterprise license seats and ~1,150 paid pilots. Key industries driving demand include cloud hyperscalers, finance (banks & trading firms), healthcare & life sciences, and adtech, with finance and healthcare together accounting for ~48% of enterprise evaluation spend. Notable regulatory evolution includes increased emphasis on model auditing and traceability requirements across US federal guidance and several state-level AI governance pilots; procurement contracts now commonly require immutable evaluation logs and model provenance records for 62% of enterprise AI projects. Technological trends accelerating adoption include automated metric orchestration, standardized evaluation SDKs, and integration of human annotation platforms into CI/CD pipelines; 71% of North American teams integrated evaluation hooks into their CI pipelines in 2024. Local players (examples) have launched hosted evaluation SaaS with built-in explainability dashboards and federated evaluation capabilities to serve regulated clients — one mid-sized US vendor reported onboarding 120 enterprises for their governance-focused evaluation product in 2024. Regional consumer behaviour: North American buyers prioritize governance, audit trails, and low-latency evaluation reporting, while developer teams emphasize integration with existing MLOps tools.
How Are Regulatory Pressures Shaping Enterprise Evaluation And Explainability?
Europe captured ~22% of global evaluation deployments in 2024 with approximately 2,400 enterprise instances and 730 active automated test suites. Key markets are Germany, the UK, and France—Germany accounts for an estimated 28% of European evaluation spend, UK 24%, and France 18%. Regulatory bodies and sustainability initiatives (EU AI Act rollout, expanded DPIA expectations, and national AI audit pilots across member states) pushed demand for explainable evaluation, immutable audit logs, and dataset impact assessments. Adoption of privacy-preserving evaluation methods (differential privacy and secure enclaves) rose, with 41% of EU-based evaluators reporting use of privacy-enhanced metrics in 2024. Emerging tech adoption included model card automation and integrated fairness checks; several European vendors extended evaluation stacks with automated bias scanners and counterfactual test generators. One regional player enhanced its evaluation suite to support multi-language fairness audits and reported a 35% increase in enterprise trials. Regional consumer behavior: buyers demand transparent, explainable evaluation results and compliance-ready reporting rather than raw performance numbers.
Which Countries Are Leading Evaluation Volume And How Are Hubs Adapting?
Asia-Pacific ranked first in growth ranking (fastest-expanding market volume in 2024) and accounted for ~30% of global model evaluation job volume with an estimated 5,100 evaluation pipelines active across enterprises and research hubs. Top consuming countries: China (1,950 pipelines), Japan (980), India (860), South Korea (420). Infrastructure trends include rapid build-out of private cloud and edge evaluation clusters — 54% of Asia-Pacific evaluation workflows ran on hybrid cloud-edge topologies in 2024 to support low-latency inference and on-device robustness tests. Innovation hubs in Beijing, Shenzhen, Tokyo and Bengaluru accelerated development of automated adversarial test suites and multilingual evaluation benchmarks. One local player introduced a low-latency, on-device evaluation agent allowing 4x faster adversarial robustness testing for mobile models; this solution saw adoption by 80+ mobile OEMs. Regional consumer behavior: strong appetite for mobile and localized-language evaluation, high tolerance for experimentation, and preference for integrated device-to-cloud evaluation flows.
How Is Market Adoption Growing Across Key South American Economies?
South America represented ~8% of global deployed evaluation capacity in 2024 with Brazil and Argentina leading the region. Brazil recorded ~420 enterprise evaluation projects and Argentina ~150 projects in 2024. Regional market share by evaluation job volume was small but growing, with Latin America recording a 22% year-on-year increase in automated evaluation runs in 2024. Infrastructure trends include reliance on regional cloud providers and hybrid on-prem models due to data sovereignty and connectivity constraints; 62% of projects used cloud-hosted evaluation orchestrators with local data connectors. Government incentives and innovation grants in Brazil for AI governance pilots (covering model audit tooling) supported uptake. One regional player launched a Spanish/Portuguese evaluation toolkit tailored for customer-facing NLP models, reporting 35 pilot deployments. Consumer behaviour: demand is driven by media localization, natural-language understanding for Portuguese and Spanish, and cost-sensitive evaluation solutions.
How Are Gulf And African Markets Deploying Governance-Focused Evaluation?
Middle East & Africa accounted for ~5% of global evaluation deployments in 2024 with major country hubs in UAE, Saudi Arabia and South Africa. Regional demand trends emphasize defense, oil & gas, and telco use cases; telcos and energy firms accounted for ~46% of evaluation revenue in the region. Major growth countries: UAE (320 evaluation projects), South Africa (210). Technological modernization includes adoption of secure evaluation enclaves and cloud-to-edge audit logging to meet industry certifications; 48% of GCC evaluation programs used encrypted audit trails in 2024. Local regulations emphasizing cybersecurity and data residency pushed enterprises to adopt federated evaluation and on-prem audit modules. One regional vendor integrated Arabic language fairness tests into its evaluation pipelines and onboarded 20 regional enterprises. Consumer behavior: emphasis on enterprise-grade security, compliance, and multi-lingual support for Arabic and English.
United States — 34% — High concentration of enterprise AI developers, large cloud infrastructure and deep MLOps ecosystems driving evaluation deployments.
China — 18% — Strong development of localized evaluation benchmarks, significant investment in evaluation automation and large-volume model validation programs.
The Market Competition Landscape for AI Model Evaluation Platforms is characterized by a mix of specialized vendors, large MLOps incumbents, and open-source ecosystems. As of 2024 there are an estimated 140–170 active competitors globally offering evaluation modules, with ~35 vendors providing end-to-end enterprise evaluation platforms and ~60 niche providers focused on a single capability (e.g., robustness testing, fairness scans, or adversarial evaluation). Market structure is moderately fragmented: the top 5 companies collectively account for roughly 42–48% of enterprise subscription revenues and 46% of large-scale deployments, while the long tail (50+ firms) services SMBs and research institutions. Strategic initiatives in 2023–2024 included 28 strategic partnerships between evaluation vendors and cloud hyperscalers, 16 mergers/acquisitions focused on integrating explainability or human-annotation capabilities, and over 120 product launches or major feature releases (e.g., automated benchmark orchestration, federated evaluation, immutable audit logs). Innovation trends shaping competition include automated human-in-the-loop pipelines (used in ~61% of enterprise pilots), integrated adversarial test suites (adopted in 44% of regulated deployments), and standardized evaluation SDKs for metric reproducibility. Pricing models vary: 56% of vendors use tiered SaaS subscriptions, 24% charge per evaluation-job, and 20% offer enterprise/perpetual licensing. Competitive positioning is driven by API maturity (average API calls per second scaled for top vendors: 150–600 cps), marketplace presence on major clouds (72% of top vendors available via at least one hyperscaler marketplace), and depth of governance features (traceable provenance, certified audit reports). For decision-makers, vendor selection typically pivots on reproducibility, regulatory reporting capabilities, and ease of integration with CI/CD pipelines.
DataRobot
Scale AI
Algorithmia
IBM Watson AI (IBM)
Microsoft Azure AI
Google Cloud AI (Vertex AI)
Databricks
Seldon (now part of another firm — exclude if subsidiary)
Truera
Robust Intelligence
Credo AI
Fiddler AI
Arize AI
Neptune.ai
Labelbox
Evidently AI
Valohai
The AI Model Evaluation Platforms market is being reshaped by a constellation of technological advances that move evaluation from ad-hoc benchmarking to continuous, governance-ready, production-grade assurance. Core technologies include automated metric orchestration engines, human-in-the-loop (HITL) annotation integrations, adversarial robustness suites, explainability modules (local and global XAI), and immutable provenance/ledgering systems for auditability. In 2024, typical enterprise evaluation stacks combined at least five evaluation modalities: performance benchmarking, robustness/adversarial testing, fairness and bias audits, explainability scoring, and security/attack surface tests. Automated metric orchestration enables teams to schedule and compare thousands of model checkpoints — in 2024, top customers executed >12,000 automated evaluation jobs per quarter on average. HITL workflows reduced false-positive drift alerts by up to 38% when integrated into evaluation pipelines; these workflows often combine crowd-sourced human annotation with expert adjudication for high-stakes domains.
Adversarial testing frameworks now incorporate gradient-based and black-box attack generators; large enterprise testbeds in 2024 executed ensembles of 7–12 adversarial strategies per model to assess real-world robustness. Explainability toolkits provide counterfactual generation, SHAP/LIME-style attributions, and concept activation vectors; enterprises increasingly require explainability outputs to be exportable as standardized model cards and included in procurement packages. Privacy-preserving evaluation techniques (secure multiparty computation, homomorphic encryption, and differential privacy) are used in ~29% of cross-organization evaluations to protect sensitive validation data. Observability and telemetry integration is another critical tech area: evaluation platforms now ingest model telemetry, dataset metadata, and inference logs to compute drift metrics, permutation importance, and alerting thresholds — enabling automated rollback triggers in CI pipelines. Standardization is emerging: evaluation SDKs and benchmark suites are being harmonized around reproducible metric schemas and machine-readable evaluation manifests to improve inter-vendor comparability. For decision-makers, key technical KPIs to track include evaluation throughput (jobs/day), mean time to detect model regression (hours), human labeling hours per flagged failure, and proportion of evaluations with certified audit reports — metrics which directly map to operational risk reduction and compliance readiness.
• In November 2023, OpenAI released the open-source Evals framework to standardize model evaluation workflows, enabling automated and human-in-the-loop evaluation harnesses for large-scale model assessment. Source: www.openai.com
• In June 2024, Hugging Face expanded its evaluation ecosystem with an updated Open LLM Leaderboard and integrated multi-metric evaluation pipelines, increasing community benchmark submissions by over 60% within three months. Source: www.huggingface.co
• In March 2024, Weights & Biases launched enhanced evaluation dashboards and automated comparison reports for model governance, reporting adoption by more than 150 enterprise teams for continuous evaluation and bias tracking. Source: www.wandb.com
• In April 2024, Google Cloud announced significant Vertex AI evaluation enhancements — including integrated evaluation pipelines and explainability exports for enterprise audit trails — leading to faster audit reporting and simplified regulatory compliance for cloud customers. Source: cloud.google.com
The scope of this AI Model Evaluation Platforms Market Report covers end-to-end evaluation needs across organizational sizes and deployment environments. The study examines product types (open-source evaluation frameworks, SaaS evaluation suites, on-prem enterprise evaluators), deployment modes (cloud, hybrid, on-prem/air-gapped), and functional modules (automated benchmarking, adversarial robustness testing, fairness & bias audits, explainability toolkits, human-in-the-loop annotation integration, telemetry and drift monitoring, and audit/provenance ledgering). Geographic coverage includes North America, Europe, Asia-Pacific, South America, and Middle East & Africa with granular country-level insights for the US, China, India, Germany, UK, Japan, Brazil, UAE, and South Africa. Application segments analyzed include finance, healthcare & life sciences, retail & e-commerce, telecom, government & defense, automotive & mobility, and cloud/hyperscale providers. Technology focus spans metric orchestration engines, adversarial testing frameworks, explainability modules (local/global), privacy-preserving evaluation techniques (differential privacy, secure enclaves), federated evaluation architectures, and integrated audit/report generators. The report also profiles vendor strategies—partnerships, product roadmaps, M&A activity—and procurement considerations for enterprise buyers, including pricing models, SLA constructs, API maturity, and marketplace availability. Analytical chapters quantify evaluation workloads, comparative vendor feature matrices, decision frameworks for vendor selection, and implementation playbooks for integrating evaluation into CI/CD and MLOps pipelines. Emerging niche segments covered include on-device evaluation for edge/IoT models, multilingual fairness benchmarks, and domain-specific evaluation suites for regulated industries. The report is structured to support decision-makers with tactical checklists, KPI benchmarks (evaluation throughput, detection latency, human labeling hours per incident), and a roadmap for scaling evaluation governance across product portfolios.
| Report Attribute/Metric | Report Details |
|---|---|
|
Market Revenue in 2024 |
USD 1,350.2 Million |
|
Market Revenue in 2032 |
USD 8,203.6 Million |
|
CAGR (2025 - 2032) |
25.3% |
|
Base Year |
2024 |
|
Forecast Period |
2025 - 2032 |
|
Historic Period |
2020 - 2024 |
|
Segments Covered |
By Type
By Application
By End-User
|
|
Key Report Deliverable |
Revenue Forecast, Growth Trends, Market Dynamics, Segmental Overview, Regional and Country-wise Analysis, Competition Landscape |
|
Region Covered |
North America, Europe, Asia-Pacific, South America, Middle East, Africa |
|
Key Players Analyzed |
OpenAI, Hugging Face, Weights & Biases, DataRobot, Scale AI, Algorithmia, IBM Watson AI (IBM), Microsoft Azure AI, Google Cloud AI (Vertex AI), Databricks, Seldon (now part of another firm — exclude if subsidiary), Truera, Robust Intelligence, Credo AI, Fiddler AI, Arize AI, Neptune.ai, Labelbox, Evidently AI, Valohai |
|
Customization & Pricing |
Available on Request (10% Customization is Free) |